
TKG Node Anti-Affinity

It is natural to assume redundancy should a node fail when using pod topology spread constraints to deploy an app across multiple nodes. This is not always the case when the nodes themselves are virtual. There is not always a way for users to know what physical host a node is running on to prevent using nodes that do not have physical redundancy due to host placement. When a host with multiple nodes goes down and takes an app that is supposed to be redundant with it, or equally bad brings down the control plane’s quorum, it can leave users scratching their head and management wanting answers. The diagram below shows a potential VM arrangement that has balance as far as the physical hosts can see. However, it may not have physical redundancy for the Kubernetes cluster's control plane and doesn’t have placement logic to ensure deployed apps also have host redundancy.
To the rescue, Tanzu Kubernetes Grid Node Anti-Affinity
Introduced/Released in Tanzu Kubernetes Grid 2.1 and 1.6.1 is the feature Node Anti-Affinity which solves this issue. Available in vSphere 7 and later Tanzu Kubernetes Grid uses Cluster Modules to put ControlPlane node VMs and Worker Nodes VM members into their own default groups. In addition, users can make their own groupings, as Node Pools shown in the diagram below called “Node Pool 1”. A VM-VM Anti-Affinity policy is associated with these Cluster Module groups and DRS takes over from there, keeping the nodes inside each grouping on separate hosts according to the policy. Nodes from different groups can run on the same host, allowing for effect use of the hardware available.

How to enable Node Anti-Affinity?
If you are on Tanzu Kubernetes Grid 1.6.1 or later with vSphere 7 or later, it is likely you already are. You can validate if Node Anti-Affinity is enabled by looking for the NodeAntiAffinity and NodeLabeling feature gates in the management cluster like the following.
kubectl config get-contexts
kubectl config set-context <MGMT-CLUSTER>-admin@<MGMT-CLUSTER>
kubectl get pods -n capv-system
kubectl get pods -n capv-system capv-controller-manager-<uuid> -o yaml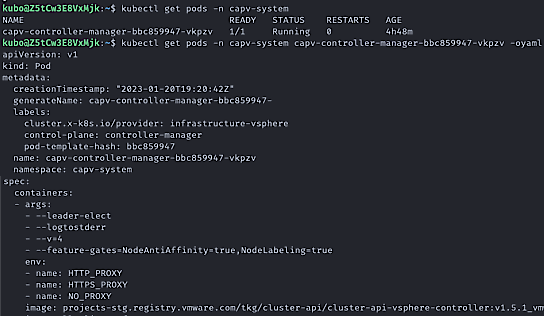
How does it work?
When a cluster deploys a Cluster Module is made for the KubeAdmControlPlane nodes. I have mentioned Cluster Modules a few times and if they don’t sound familiar, that is okay, they are not directly interacted with but utilized by APIs. Cluster Modules were introduced in vSphere 7 as a way to programmatically create groups of VMs within a vSphere cluster to define configurations for all the members of that group. Such as DRS placement properties, allowing vSphere a way to know which group of VMs relate to each other. We can see these Cluster Modules from the vCenter by using the govc CLI.
When a machine object is created it will include the label “node.cluster.x-k8s.io/esxi-host” that will have the hostname or IP if the hostname is not defined. The same label is also seen when looking at the node with kubectl. This label is what users can use to know what hosts their pods are running on when they want the app to have redundancy across physical hardware. More about this in the next section. Below are examples of the label.
kubectl get machines tkg-vc-antrea-<uuid> -o json path =’{.metadata.labels}’ | jq.
kubectl get nodes
kube get nodes tkg- vc-antrea-<uuid> -o json path =’{.metadata.labels}’ | jq.
How to ensure pods deploy to nodes that are running on different hosts
The Cluster Modules UUIDs used by a cluster can be seen by looking at the vsphereclusters object with the kubectl CLI. When the VSphereVM object is created as part of the process of ClusterClass creating the Nodes for the control plane, it has be changes to store the Cluster Module UUID and ESXI host the VM is placed on. The hostname is then passed to the machine object as the label “node.cluster.x-k8s.io/esxi-host”. And then the node gains the label keyword “node.cluster.x-k8s.io/esxi-host”. Using these labels with topology spread constraints, a node pool can have more nodes than physical hosts, but still deploy deployments redundantly across both nodes and hosts, if the number of pods is less than the number of hosts when using a maxSkew of 1. Labels can also be added to a user created node pool if a user wanted to keep their deployment limited to a particular node pool in a cluster. Below is an example that limits one pod per host that can be used with deploying a deployment.
---
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
# Configure a topology spread constraint
topologySpreadConstraints:
- maxSkew: 1
topologyKey: node.cluster.x-k8s.io/esxi-host
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabelKeys: <list> # optional; alpha since v1.25
### other Pod fields go here
There’s a lot of new features in Tanzu Kubernetes Grid 2.1. Download the latest release and give it a try and visit the documentation for getting started. Also, visit Tanzu TechZone Activity Path for more information about Tanzu Kubernetes Grid.